
I Built the Same B2B Document Extractor Twice: Regex-Rules vs. LLM
A small experiment with OCR, Regex, and a local LLM that says a lot about the future of document automation

Imagine you process B2B order forms every day. In theory, all documents contain the same information:
customer ID
purchase order number
delivery date
ordered items
In practice, however, every customer structures the PDF differently.
One company writes “PO Number”.
Another uses “Order Reference”.
A third one invents its own naming convention entirely.
For us humans, this is trivial.
For traditional automation pipelines, it often needs a lot maintenance.
This week, I recreated exactly this scenario with two approaches:
OCR + Regex Rules
OCR + a local LLM running via Ollama and LLaMA 3
☕👉 I turned the full experiment into a detailed step by step guide on Towards Data Science, including the comparison and full GitHub code:
I Built the same B2B Document Extractor Twice
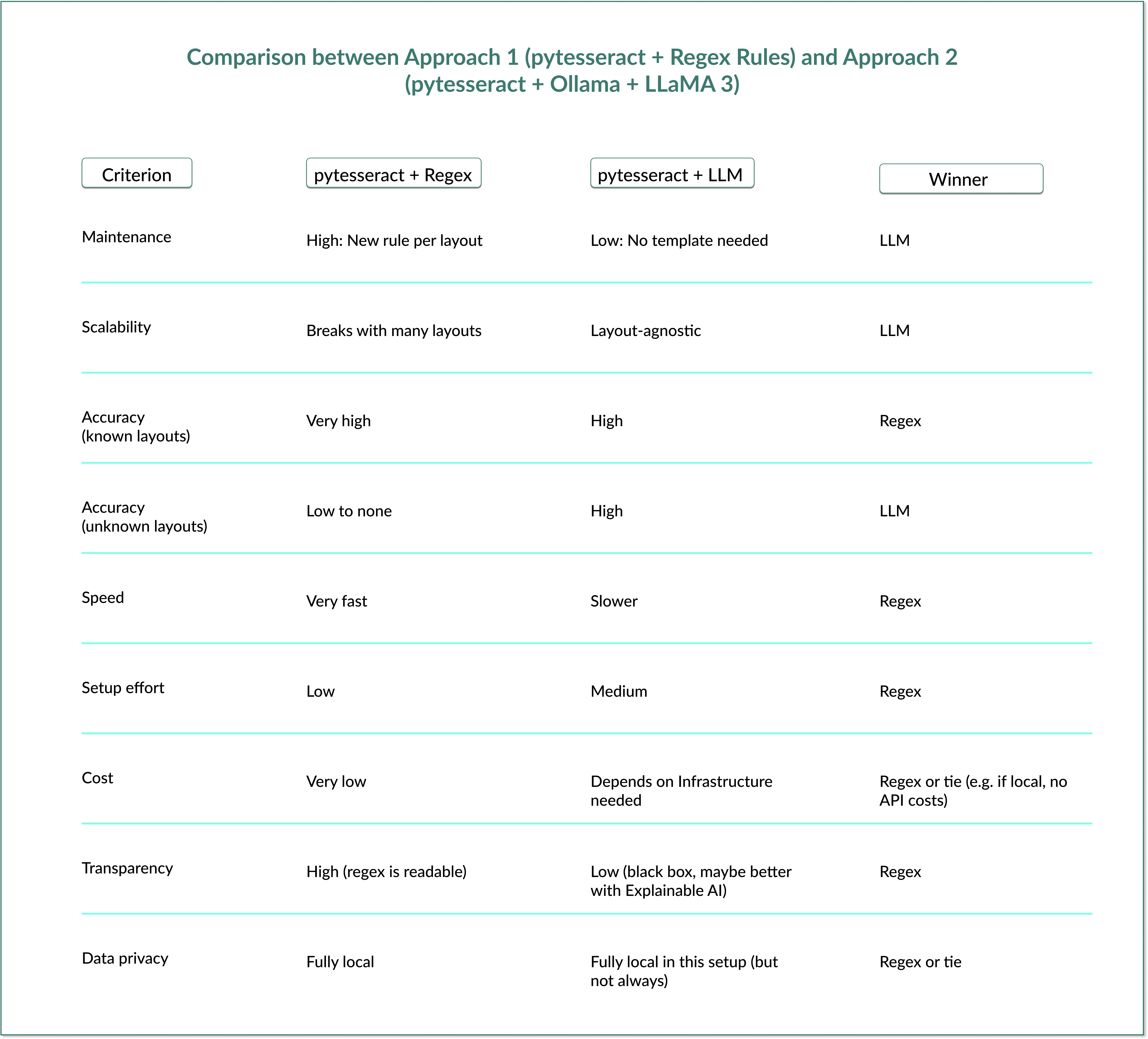
The interesting insight was where the complexity lives.
With regex pipelines, it sits inside the rules:
new customer → new regex
changed layout → broken extraction
growing number of formats → growing maintenance overhead
With LLM pipelines, the complexity shifts more to inference time, infrastructure, monitoring and model behavior.
And that changes the strategic discussion completely.
The question is often not: “Is the LLM more accurate?”
The more important question becomes: “At what point does maintaining hundreds of extraction rules become more expensive than operating an LLM pipeline?”
One thing I also found important while building this, and where I think many AI discussions currently become too simplistic:
LLMs are not automatically the better solution. If documents are highly standardized, regex is often still the cleaner, faster, cheaper, and more explainable approach.
If this post was helpful, hit ❤️ to help others discover it or share it with someone who might enjoy it 🤓. Thanks!
I’d love your thoughts on this:
I’m considering adding a separate “Tool Reviews” section to this Substack. I get approached quite often for AI and data tool collaborations with affiliate links, and I’m thinking about testing some of these tools transparently in a clearly separated section, while keeping the regular articles fully independent.
Would that be interesting to you, or would you prefer this Substack to stay purely educational?
New here? Or curious what other readers loved from Data Science Espresso?
As a subscriber to Data Science Espresso, you get free access to some of my most-read articles through Friend Links.
The Smarter Way to Write Your Thesis: OneNote Meets LaTeX → Friend link (no Medium account needed)
RAG in Action: Build your Own Local PDF Chatbot as a Beginner → Friend link (no Medium account needed)
How to study Math-Heavy Topics like Reinforcement Learning → Friend link (no Medium account needed)
AI, Cancer Cells & a Master’s Student’s Journey to a Harvard Postdoc → Friend link (no Medium account needed)
CSV Plot Agent with LangChain & Streamlit: Your Introduction to Data Agents → Friend link (no Medium account needed)
Thanks for reading.
Sarah 💕🥳🚀
